
转:
为什么TCP 会粘包
前几天,调试mina的TCP通信, 第一个协议包解析正常,第二个数据包不完整。为什么会这样吗,我们用mina这样通信框架,还会出现这种问题? 带者问题,我们先分析一下问题。
提到通信, 我们面临都通信协议,数据协议的选择。 通信协议我们可选择TCP/UDP:
- TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 即面向流的通信是无消息保护边界的。
- UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息),这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。
由于TCP无消息保护边界, 需要在消息接收端处理消息边界问题。也就是为什么我们以前使用UDP没有此问题。 反而使用TCP后,出现少包的现象。
粘包的分析
- 正常情况,发送及时每消息发送,接收也不繁忙,及时处理掉消息。像UDP一样.
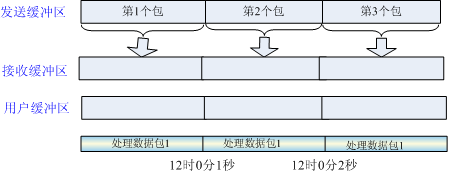
- 发送粘包,多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包. 这种情况和客户端处理繁忙,接收缓存区积压,用户一次从接收缓存区多个数据包的接收端处理一样。
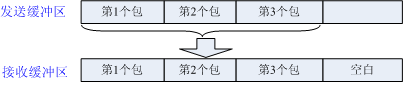
- 发送粘包或接收缓存区积压,但用户缓冲区大于接收缓存区数据包总大小。此时需要考虑处理一次处理多数据包的情况,但每个数据包都是完整的。
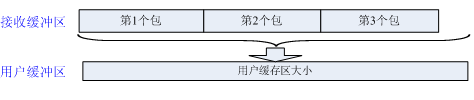
- 发送粘包或接收缓存区积压, 用户缓存区是数据包大小的整数倍。 此时需要考虑处理一次处理多数据包的情况,但每个数据包都是完整的。
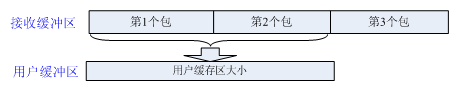
- 发送粘包或接收缓存区积压, 用户缓存区不是数据包大小的整数倍。 此时需要考虑处理一次处理多数据包的情况,同时也需要考虑数据包不完整。
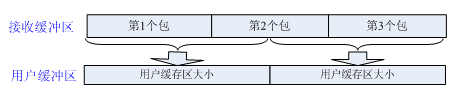
- 发送端需要等缓冲区满才发送出去,造成粘包
- 接收方不及时接收缓冲区的包,造成多个包接收
如何应对
- 连续的数据流不需要处理。如一个在线视频,它是一个连续不断的流, 不需要考虑分包。
- 每发一个消息,建一次连接的情况。
- 发送端使用了TCP强制数据立即传送的操作指令push。
- UDP, 前面已说明白了。在这在强调一下,UDP不需要处理,免的忘记了。
- 如果用socket编写编程的话, 我就不多说我, 可参考下面的资料:
- Grizzly: http://grizzly.java.net/nonav/docs/docbkx2.0/html/coreframework-samples.html User Guide 第二章的样例:解析收到的消息。
- xSocket:http://xsocket.sourceforge.net/core/tutorial/V2/TutorialCore.htm 第 18 节。
- Netty: http://netty.io/docs/3.2.6.Final/api/org/jboss/netty/handler/codec/frame/FrameDecoder.html FrameDecoder 的 API 文档。Netty 抽象了一个“消息桢解码器”的类来处理这些。
- Mina 2:http://mina.apache.org/chapter-11-codec-filter.html
- Mina 2:如果En文不好的话, 可参考http://freemart.iteye.com/blog/836654。 它在判断包是否完整时,有个小缺陷,它没使用IOBuffer的prefixedDataAvailable。但注释写的比较好。
public class ImageResponseDecoder extends CumulativeProtocolDecoder {
/**
* 返回值的解释:
* 1、false, 继续接收下一批数据,有两种情形,如缓冲区数据刚刚就是一个完整消息,或不够一条消息时。如果不够一条消息,那么会将下一批数据和剩余消息进行合并
* 2、true, 当缓冲区的消息多于一条消息时,剩余消息会再会推送至doDecode
*/
protected boolean doDecode(IoSession session, IoBuffer in, ProtocolDecoderOutput out)throws Exception {
//发送数据时,头四个字节记录了消息的长度。 此方法会读四个字节,并和实现流长度对比。返回前,将流reset.
if (in.prefixedDataAvailable(4)) {
int length = in.getInt();
byte [] bytes = newbyte[length];
in.get(bytes);
ByteArrayInputStream bais =new ByteArrayInputStream(bytes);
BufferedImage image = ImageIO.read(bais);
out.write(image);
return true;//如果读取内容后还粘了包,系统会自动处理。
}else{
returnfalse;//继续接收数据,以待数据完整
}
}
}
- 再总结一下处理流程: 就发送数据时,包开始写入消息长度n, 当接收到的缓存区数据m,各处理流程如下:
- 1)若n<m,则表明数据流包含多包数据,从其头部截取n个字节存入临时缓冲区,剩余部分数据依此继续循环处理,直至结束。或n>m
- 2)若n=m,则表明数据流内容恰好是一完整结构数据,直接将其存入临时缓冲区即可。
- 3)若n >m,则表明数据流内容尚不够构成一完整结构数据,需留待与下一包数据合并后再行处理。



相关推荐
Socket编程TCP粘包问题及解决方案.docx
主要为大家详细介绍了C#中TCP粘包问题的解决方法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
发生TCP粘包或拆包有很多原因,现列出常见的几点,可能不全面,欢迎补充, 1、要发送的数据大于TCP发送缓冲区剩余空间大小,将会发生拆包。 2、待发送数据大于MSS(最大报文长度),TCP在传输前将进行拆包。 3、...
通过socket通讯实现服务器与客户端的连接。首先服务器利用udp广播发送自己的ip地址,客户端在收到广播后通过此ip以tcp连接的方式连接服务器来通讯。
本demo模拟了TCP通信中发送端和接收端的行为,并利用序列化和反序列化的思想,自定义协议来解决TCP的粘包和拆包问题。
利用网络通信中,经常会出现粘包的问题,围绕着这个问题说原因和解决的蛮多帖子的,但是给出粘包代码的就好少,为了便于大家更好的理解粘包的问题,这里对客户端和服务器端出现的粘包问题进行模拟
C#实现Socket编程 (异步通讯,解决Tcp粘包)
主要给大家介绍了Golang TCP粘包拆包问题的解决方法,文中通过示例代码介绍的非常详细,对大家学习或者使用Golang具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧
Socket通信,通过异步,解决粘包问题
socket tcp如何防止多次send的包被合成一个包(粘包)发送.zip
C#解决socket通信过程中粘包分包问题,本项目是一个只有6个C#代码文件的开源小工程,用来学习基于TCP的套接字通信包,可以自定义通信协议,处理分包和粘包,内置一个服务端和客户端的套接字程序,也有测试代码和对应...
资料文件用于解决C#编程中发生的粘包问题的处理
解决socket TCP网络传输粘包问题
当前在网络传输应用中,广泛采用的是TCP/IP通信协议及其标准的socket应用开发编程接口(API)。TCP/IP传输层有两个并列的协议:TCP和UDP。其中TCP(transport control protocol,传输控制协议)是面向连接的,提供高...
完美解决粘包!!值不值你说了算
主要介绍了python TCP Socket的粘包和分包的处理详解,分享了相关代码示例,小编觉得还是挺不错的,具有一定借鉴价值,需要的朋友可以参考下
你无须了解如何使用 Socket, 如何维护 Socket 连接和 Socket 如何工作,我们可以有更多的时间用在业务逻辑上,SuperSocket有效的利用自己的协议解决粘包及各种事件通知机制。 GitHub地址: 实现功能: 心跳检测 断线...
GOLANG语言实现SOCKET通讯粘包问题解决示例,对于TCP传输分段,组合无明显界线,造成传输和接收数据包不完整的解决方法!